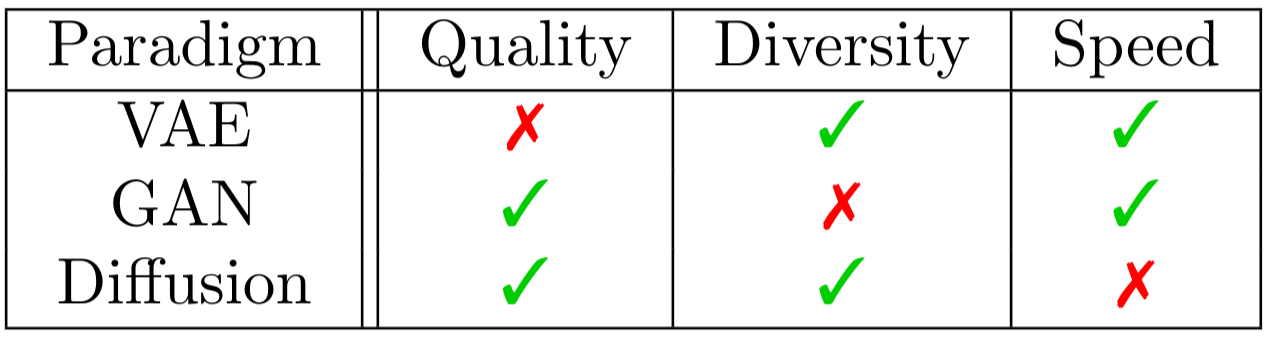
What LLM Coding Benchmarks Actually Measure (and What They Don't)
AI coding assistants (Cursor, Claude Code, Antigravity, etc.) no longer need an introduction. Many of these tools let you choose the underlying LLM, and that choice definitely matters. However, with so many models on the market—and new ones coming out every few weeks—how do you make that choice?
Benchmarks are the obvious place to look. But how should you use them? And if you’ve followed this space even a little, you’ve probably heard plenty of criticism: benchmark gaming, training contamination, misaligned tasks, and so on. So are benchmarks useful at all?
A colleague recently asked me this, which triggered a longer train of thought that I wanted to write down.
Read more →